Building Robust Machine Learning Models for Fraud Detection in Python: A Comprehensive Guide
In today's digital economy, the battle against financial fraud is more critical than ever. Organizations across various sectors are grappling with sophisticated fraudulent activities that can lead to significant financial losses and reputational damage. This comprehensive guide will walk you through the essential steps on how to build a machine learning model for fraud detection in Python, empowering you to leverage the power of artificial intelligence to safeguard your assets. We'll explore everything from data preparation and feature engineering to model selection, evaluation, and deployment, providing actionable insights for professionals seeking to implement cutting-edge fraud analytics solutions.
Understanding the Landscape: Why Machine Learning is Crucial for Fraud Detection
Traditional rule-based systems, while foundational, often struggle to keep pace with the evolving nature of fraud. Fraudsters constantly adapt their tactics, making static rules obsolete. This is where machine learning algorithms step in, offering dynamic, adaptive capabilities to identify patterns and anomalies that human analysts or fixed rules might miss. By analyzing vast amounts of transaction data, machine learning models can learn to distinguish legitimate activities from suspicious ones, significantly improving detection rates and reducing false positives.
The sheer volume and velocity of modern financial transactions necessitate an automated approach. Whether it's credit card fraud, insurance claims fraud, e-commerce scams, or cyber fraud, the underlying principle often involves identifying deviations from normal behavior. Machine learning, particularly techniques like anomaly detection, is uniquely suited for this challenge, providing a proactive defense against financial crime.
Key Benefits of ML for Anti-Fraud Efforts:
- Enhanced Accuracy: Machine learning models can uncover intricate, non-obvious patterns indicative of fraud.
- Scalability: Process millions of transactions in real-time, something manual review simply cannot achieve.
- Adaptability: Models can be continuously retrained to learn new fraud patterns as they emerge.
- Reduced False Positives: Advanced models can minimize flagging legitimate transactions as fraudulent, improving customer experience.
- Cost Efficiency: Automating detection reduces the need for extensive manual reviews, optimizing operational costs.
The Machine Learning Model Development Lifecycle for Fraud Detection
Building an effective fraud detection system in Python involves a structured, iterative process. Each stage is crucial and contributes to the overall robustness and performance of your predictive model. Let's delve into these stages, providing practical advice at each step.
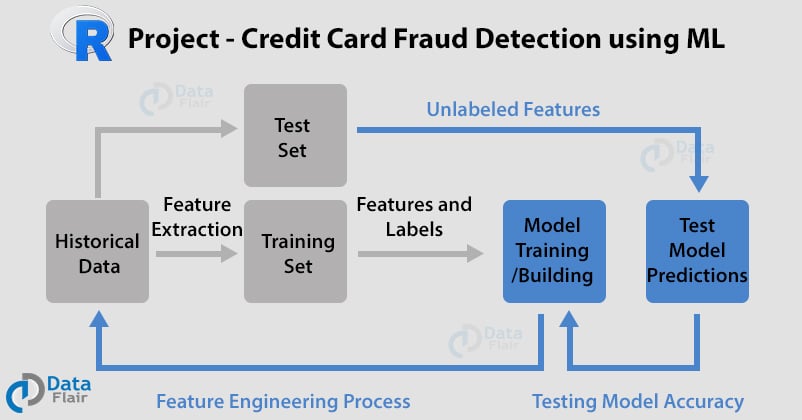
Step 1: Data Collection and Understanding
The foundation of any successful machine learning model is high-quality data. For fraud detection, this typically involves collecting historical transaction data, customer information, device data, and potentially external data sources. It's vital to have a dataset that contains both legitimate and fraudulent transactions, clearly labeled if you're pursuing a supervised learning approach.
- Identify Data Sources: This could include internal databases (CRM, ERP, transaction logs), payment gateways, public records, or third-party data providers.
- Data Exploration (EDA): Use Python libraries like Pandas and Numpy to explore your data. Understand its structure, identify data types, distributions, and initial patterns. Visualize key variables using Matplotlib or Seaborn to spot anomalies or correlations.
- Understand the Fraud Labels: Ensure your fraudulent transactions are accurately labeled. In real-world scenarios, fraud labels might be scarce or delayed, posing a significant challenge.
Expert Tip: Spend ample time in this phase. A deep understanding of your data will guide your preprocessing and feature engineering decisions, directly impacting model performance. Inaccurate or incomplete data can derail even the most sophisticated algorithms.
Step 2: Data Preprocessing and Cleaning
Raw data is rarely ready for direct model training. This stage involves transforming raw data into a clean, structured format suitable for machine learning algorithms. This is a critical step in building any machine learning model for fraud detection.
- Handling Missing Values: Decide how to treat missing data. Options include imputation (mean, median, mode, or more advanced methods like K-NN imputation) or removal of rows/columns, depending on the extent of missingness.
- Outlier Detection and Treatment: Fraudulent transactions often appear as outliers. While some outliers might be fraud, others could be data entry errors. Techniques like Z-score, IQR, or Isolation Forest can help identify them. Carefully consider whether to remove, transform, or keep outliers, as they might hold valuable fraud signals.
- Data Normalization/Standardization: Scale numerical features to a standard range (e.g., 0-1 for normalization, mean 0 and variance 1 for standardization). This prevents features with larger values from dominating the learning process, especially for distance-based algorithms.
- Encoding Categorical Variables: Convert categorical data (e.g., 'payment_method', 'country') into numerical representations using techniques like One-Hot Encoding, Label Encoding, or Target Encoding.
- Addressing Imbalanced Datasets: Fraud datasets are notoriously imbalanced, with legitimate transactions vastly outnumbering fraudulent ones. This is perhaps the single most challenging aspect of fraud detection. If not addressed, models tend to be biased towards the majority class, resulting in poor fraud detection.
For imbalanced datasets, consider these techniques:
- Resampling Techniques:
- Oversampling: Duplicate minority class samples (e.g., Random Oversampling) or generate synthetic samples (e.g., SMOTE - Synthetic Minority Over-sampling Technique).
- Undersampling: Reduce the number of majority class samples (e.g., Random Undersampling, Tomek Links, ENN).
- Cost-Sensitive Learning: Assign higher penalties to misclassifications of the minority class during model training.
- Ensemble Methods: Use algorithms like BalancedBaggingClassifier or EasyEnsemble.
Step 3: Feature Engineering for Enhanced Detection
This is often where the magic happens in fraud detection. Feature engineering involves creating new features from existing raw data to help the machine learning model better understand the underlying patterns. This requires domain expertise and creativity.
- Temporal Features: Time-based features are crucial. Examples include:
- Time since last transaction.
- Number of transactions in the last hour/day/week for a specific user/IP/card.
- Average transaction amount in a time window.
- Aggregation Features: Summarize transaction behavior.
- Total amount spent by a user in the last 24 hours.
- Number of unique merchants visited by a user.
- Ratio of current transaction amount to average historical transaction amount.
- Velocity Features: Measure the speed or frequency of events.
- Number of failed login attempts from an IP address in a short period.
- Number of distinct payment methods used by a user within an hour.
- Ratio Features: Ratios between different aggregated features can highlight suspicious activities.
- Interaction Features: Combine two or more features (e.g., 'amount' 'number_of_items').
Practical Advice: Collaborate closely with domain experts (e.g., fraud analysts) to brainstorm and validate potential features. Their insights into how fraudsters operate are invaluable for creating impactful features that truly capture suspicious behavior.
Step 4: Model Selection and Training
With clean, engineered features, you're ready to select and train your machine learning algorithms. This step involves splitting your data, choosing appropriate models, and optimizing their performance.
- Data Splitting: Divide your dataset into training, validation, and test sets (e.g., 70% training, 15% validation, 15% testing). Ensure the split maintains the original class distribution, especially for imbalanced datasets (stratified splitting).
- Algorithm Selection: For supervised fraud detection, popular choices include:
- Logistic Regression: A good baseline, simple and interpretable.
- Decision Trees: Intuitive, can capture non-linear relationships.
- Random Forests: Ensemble of decision trees, robust to overfitting, highly effective.
- Gradient Boosting Machines (GBMs): Algorithms like XGBoost, LightGBM, and CatBoost are state-of-the-art for tabular data, known for their high performance in fraud detection challenges.
- Support Vector Machines (SVMs): Effective for complex datasets but can be computationally intensive.
- Neural Networks: For highly complex patterns or large datasets, especially with sequential data (e.g., transaction sequences), deep learning frameworks like TensorFlow or Keras can be explored.
- Model Training: Use your training data to fit the chosen model. Python's Scikit-learn library provides robust implementations for most of these algorithms.
- Hyperparameter Tuning: Optimize model performance by adjusting hyperparameters. Techniques include Grid Search, Random Search, or more advanced methods like Bayesian Optimization. Cross-validation is essential here to prevent overfitting to the training data.
Call to Action: Begin experimenting with different algorithms and hyperparameter configurations to discover the optimal model for your specific fraud detection challenge.
Step 5: Model Evaluation and Performance Metrics
Evaluating a fraud detection model requires specific metrics beyond simple accuracy, especially due to the imbalanced nature of the data. A high accuracy can be misleading if the model simply predicts the majority class (legitimate transactions) most of the time.
- Confusion Matrix: The cornerstone of classification evaluation. It breaks down predictions into:
- True Positives (TP): Correctly identified fraud.
- True Negatives (TN): Correctly identified legitimate.
- False Positives (FP): Legitimate transactions incorrectly flagged as fraud (Type I error).
- False Negatives (FN): Fraudulent transactions missed by the model (Type II error).
- Precision: Of all transactions flagged as fraud, how many were actually fraud?
TP / (TP + FP). High precision means fewer false alarms. - Recall (Sensitivity): Of all actual fraudulent transactions, how many did the model correctly identify?
TP / (TP + FN). High recall means catching more fraud. - F1-Score: The harmonic mean of Precision and Recall. Useful when you need a balance between the two.
- ROC-AUC Curve: Receiver Operating Characteristic - Area Under the Curve. Plots the True Positive Rate against the False Positive Rate at various threshold settings. A higher AUC indicates better model performance across different thresholds. It's an excellent metric for imbalanced datasets.
- Cost-Sensitive Evaluation: Consider the actual costs associated with false positives (investigation costs, customer dissatisfaction) versus false negatives (financial loss due to undetected fraud). Adjust your model's threshold to optimize for your specific business objectives.
Important Note: For fraud detection, recall is often prioritized to minimize financial losses, even if it means a slightly higher rate of false positives. However, a balance must be struck to avoid overwhelming fraud investigation teams or inconveniencing legitimate customers.
Step 6: Model Deployment and Monitoring
Building the model is only half the battle. To realize its value, the model must be deployed into a production environment and continuously monitored.
- Deployment Strategy:
- Batch Processing: For less time-sensitive fraud, models can score transactions periodically.
- Real-time/Online Processing: For immediate decisions (e.g., credit card transactions), the model needs to be integrated into the transaction pipeline, often via APIs (e.g., using Flask or FastAPI in Python).
- Integration: Seamlessly integrate the model's predictions into existing fraud detection systems or operational workflows.
- Continuous Monitoring: Models can degrade over time due to concept drift (fraud patterns change) or data drift (input data characteristics change).
- Monitor key performance metrics (Precision, Recall, F1-score, AUC) on live data.
- Track prediction distributions and feature drift.
- Implement alert systems for significant performance drops.
- Feedback Loop and Retraining: Establish a robust feedback mechanism. When new fraud is confirmed or legitimate transactions are misclassified, this information should be used to retrain the model periodically. This ensures the model remains adaptive and effective against evolving threats.
Actionable Tip: Consider MLOps practices to automate deployment, monitoring, and retraining pipelines. Tools like MLflow, Kubeflow, or cloud-specific ML platforms (AWS SageMaker, Google AI Platform, Azure Machine Learning) can streamline this process.
Advanced Considerations for Robust Fraud Detection
Beyond the core steps, several advanced topics can significantly enhance your machine learning model for fraud detection.
Ethical AI and Bias
Ensure your models are fair and unbiased. Biases in historical data can lead to discriminatory outcomes. Regularly audit your model's predictions across different demographic groups or transaction types to identify and mitigate biases. This is crucial for responsible AI development.
Explainable AI (XAI) for Risk Assessment
In fraud detection, simply knowing if a transaction is fraudulent isn't always enough. Investigators often need to understand why a transaction was flagged. XAI techniques like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) can provide insights into feature importance and individual prediction explanations, aiding in risk assessment and compliance.
Scalability and Performance
As transaction volumes grow, your system must scale. Optimize your Python code for performance, consider distributed computing frameworks (e.g., Apache Spark with PySpark), and leverage cloud infrastructure for elastic scalability.
Deep Learning Approaches
For sequential transaction data or complex unstructured data (e.g., text from customer support interactions, image data from documents), deep learning models like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTMs), or Convolutional Neural Networks (CNNs) can be powerful. These models can automatically learn intricate features from raw data, reducing the need for manual feature engineering.
Graph Neural Networks (GNNs)
Fraud often involves networks of interconnected entities (users, devices, accounts). Graph Neural Networks can model these relationships and detect fraudulent communities or suspicious connections, adding another layer of sophistication to your fraud analytics.
Practical Python Libraries for Fraud Detection
Python's rich ecosystem of libraries makes it the go-to language for building machine learning solutions. Here are some indispensable ones:
- Pandas: For efficient data manipulation and analysis. Essential for data cleaning, transformation, and feature engineering.
- NumPy: Provides fundamental numerical operations, especially for array computations.
- Scikit-learn: The workhorse for traditional machine learning algorithms, including classification, regression, clustering, and preprocessing tools.
- Imbalanced-learn: An invaluable library for handling imbalanced datasets, offering various oversampling and undersampling techniques like SMOTE.
- XGBoost, LightGBM, CatBoost: Highly optimized gradient boosting libraries known for their speed and accuracy on tabular data.
- Matplotlib & Seaborn: For powerful data visualization, crucial for exploratory data analysis and presenting model results.
- TensorFlow / Keras & PyTorch: For building and training deep learning models, especially useful for complex, large-scale problems or when dealing with unstructured data.
- SHAP & LIME: For model interpretability and explainability, helping to understand why a model makes certain predictions.
Frequently Asked Questions
What are the biggest challenges when building a machine learning model for fraud detection?
The primary challenges include the extreme class imbalance (far more legitimate transactions than fraudulent ones), the dynamic nature of fraud (fraud patterns constantly evolve), data quality issues (missing values, noisy data), and the need for explainability in sensitive financial contexts. Additionally, ensuring data privacy and regulatory compliance adds another layer of complexity to building effective fraud detection systems.
How important is feature engineering in fraud detection models?
Feature engineering is critically important, often more so than the choice of machine learning algorithm itself. Raw transaction data rarely contains all the necessary signals for detecting sophisticated fraud. Creating new, insightful features (like velocity features, aggregated spending patterns, or ratios) based on domain expertise can significantly boost a model's ability to identify subtle fraudulent behaviors that would otherwise be missed. It transforms raw data into a language the model can understand more effectively for risk assessment.
Can machine learning models completely replace human fraud analysts?
While machine learning models significantly automate and enhance fraud detection capabilities, they are best viewed as powerful tools that augment, rather than completely replace, human analysts. Models excel at identifying patterns in vast datasets and flagging suspicious activities. However, human analysts provide invaluable context, investigate complex cases, handle edge scenarios, adapt to truly novel fraud schemes, and make final decisions that often require nuanced judgment and interaction with customers. The most effective anti-fraud strategies involve a synergistic combination of advanced fraud analytics and expert human oversight.
0 Komentar